CPU/GPU Multiprecision Mandelbrot Set
Eric Bainville - Dec 2009Benchmarks
Update (May 2010). I updated the benchmarks to include new NVidia and AMD drivers.
I run the tests on two machines:
Machine A: CPU Intel Core i7 920 (4 cores, 8 threads) @3.33 GHz (overclocked) Chipset Intel X58 6GB of DDR3 @1.33 GHz GPU ATI Radeon HD5870 1GB Machine B: CPU Intel Core 2 Quad Q9550 (4 cores) @2.83 GHz (stock speed) Chipset Intel P45 12GB of DDR2 @800 MHz GPU NVidia GTX285 1GB
On each machine I run the tests on two systems:
Linux 64-bit kernel-2.6.32 glibc-2.10.1 gcc-4.3.4 NVidia driver 195.36.24 + NVidia SDK 3.0 Catalyst 9.12 Hotfix + Stream SDK 2.0 (not updated yet) Windows 7 64-bit vs2008-sp1 (/fp:fast) NVidia dev driver 197.13 + CUDA toolkit 3.0 Catalyst 10.4 + Stream SDK 2.1


Each test computes a 2048x2048 image of a specific site. Code is either multithreaded C (C x8 means "8 threads"), or OpenCL. In the tables, DNF means "Did Not Finish", either system freeze or driver timeout, and TBU means "To Be Updated", as I did not run the tests with the latest drivers. The green (resp. red) cell for each site highlight the best GPU (resp. CPU) time.
Site Mini Set 1 Center X -0.15710375803 Center Y +1.03258348530 Pixel step +0.0000375 Site Julia Island (ref.: Mandelbrot zoom from the Wikipedia page) Center X -0.7436438870371587100514222 Center Y +0.1318259042053126002256675 Pixel step +0.00000000000002
Hardware float
| Mini Set 1 | Julia Island | |||
|---|---|---|---|---|
| Device, Code | Linux | Windows | Linux | Windows |
| Q9550, C x8 | 150ms | 130ms | 6.9s | 5.5s |
| Core i7, C x8 | 78ms | 97ms | 3.1s | 2.5s |
| Core i7, OpenCL | TBU | 130ms | TBU | 2.6s |
| GTX285, OpenCL | 41ms | 48ms | 200ms | 209ms |
| HD5870, OpenCL | TBU | 52ms | TBU | 200ms |
Hardware double
| Mini Set 1 | Julia Island | |||
|---|---|---|---|---|
| Device, Code | Linux | Windows | Linux | Windows |
| Q9550, C x1 | 560ms | 555ms | 48s | 38s |
| Q9550, C x8 | 156ms | 129ms | 12s | 9.6s |
| Core i7, C x1 | 396ms | 397ms | 33s | 31s |
| Core i7, C x8 | 70ms | 95ms | 4.8s | 4.3s |
| Core i7, OpenCL | TBU | 120ms | TBU | 4.4s |
| GTX285, OpenCL | 77ms | 100ms | 2.1s | 2.7s |
| HD5870, OpenCL | TBU | 58ms | TBU | 1.0s |
fp128
Here, the C code is the code described in Fixed Point Reals. This code is not optimized, and could probably be accelerated using SSE extensions. The OpenCL is described in fp128 for OpenCL.
| Mini Set 1 | Julia Island | |||
|---|---|---|---|---|
| Device, Code | Linux | Windows | Linux | Windows |
| Q9550, C x8 | 4.5s | 3.8s | 370s | 370s |
| Core i7, C x8 | 3.5s | 3.0s | 300s | 260s |
| Core i7, OpenCL | TBU | 6.5s | TBU | 274s |
| GTX285, OpenCL | 4.2s | 4.2s | DNF | 160s |
| HD5870, OpenCL (wg=8) | TBU | 1.8s | TBU | 72s |
Comments on the benchmarks
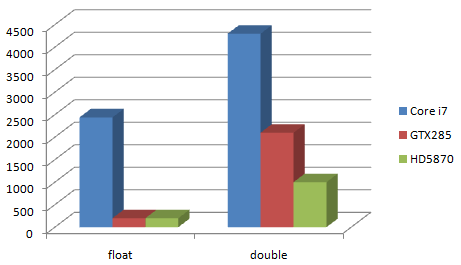
We see here the excellent performance of the GPU hardware float units over the CPU. For the most intensive computations (Julia Island), we have a 12x speed ratio between the fastest CPU and the GPU's in single precision. In double precision, the HD5870 is 4x faster than the CPU, and the GTX285 is 2x faster than the CPU. For fp128, we get a 4x speedup over the CPU for the HD5870, and 2x for the GTX285.
Note the nice performance of OpenCL running on the Core i7. OpenCL provides a credible alternative to more demanding programming options (threads, SSE).
I included C single thread timing to highlight the excellent performance of the 2 hardware threads per core (HyperThreading) in the Core i7. Both processors have 4 cores, but running 8 threads provides a 4x improvement on the Q9550, and a 8x improvement on the Core i7.
The fp128 running times depend significantly on the choice of the subdivision parameters: number of kernels, number of threads, and workgroup size.
Let's conclude with some general remarks, keeping in mind they are based only on a very small set of benchmarks and in a single application: take them with a grain of salt...
- OpenCL using vectors runs on a CPU at the same speed as multithreaded C code (without the trouble of managing threads and writing SSE code).
- Expect a 10x GPU/CPU speed gain for float, HD5870 and GTX285 are equivalent.
- Expect a 4x GPU/CPU speed gain for double, HD5870 is 2x to 4x faster than GTX285.
- Expect a 2x GPU/CPU speed gain for general integer computations.
| GPU Mandelbrot Set : fp128 for OpenCL | Top of Page | GPU Benchmarks |
