OpenCL Fast Fourier Transform
Eric Bainville - May 2010One work-group per DFT (1)
We will now distribute the computation of each DFT between all threads of one work group. The idea is to load all inputs of the radix-2r DFT in shared memory, then compute the DFT on r threads in a work-group using a simple pattern similar to our first radix-2 kernel. This can be translated into the following kernel:
__kernel void fft_radix_r(__global const float2 * x,__global float2 * y,__local float2 * u,int p) { int r = get_local_size(0); // thread count in group int i = get_local_id(0); // current thread in group, in 0..R-1 int k = get_group_id(0)&(p-1); // index in input sequence, in 0..P-1 int j = (get_group_id(0)-k)*2*r+k; // index in output sequence (insert LOG2(2*R) zeros) // Load and scale 2*R values in U[2*R] (shared memory) float alpha = -M_PI*(float)k/(float)(r*p); float sn,cs; sn = sincos((float)i*alpha,&cs); u[i] = mul( (float2)(cs,sn), x[get_group_id(0) + i * get_num_groups(0)] ); sn = sincos((float)(i+r)*alpha,&cs); u[i+r] = mul( (float2)(cs,sn), x[get_group_id(0) + (i+r) * get_num_groups(0)] ); // Compute in-place DFT of U[2*R] using R threads float2 a,b; for (int bit = r;bit > 0;bit >>= 1) { int di = i&(bit-1); // Index in sequence of length BIT int i0 = (i<<1)-di; // Insert 0 at position BIT int i1 = i0 + bit; // The other input of the butterfly sn = sincos((float)di*(-M_PI)/(float)(bit),&cs); // Twiddle factor a = u[i0]; b = u[i1]; u[i0] = a + b; u[i1] = mul( (float2)(cs,sn), a - b); barrier(CLK_LOCAL_MEM_FENCE); // Sync U between iterations } // Store R values y[j+i*p] = u[revbits(2*r,i)]; y[j+(i+r)*p] = u[revbits(2*r,i+r)]; }
Since the DFT is in-place in u, the result is permuted with a reverse binary transform. revbits(p,i) returns i with i mod p binary reversed. p must be a power of 2.
With n=224, using the same work-group size at each kernel call, we can check r=1,2,4,8,32,128: 2r must divide n, and the work-group size is limited by OpenCL (to 512 on the GTX285, and 256 on the HD5870).
| radix-r | GTX285 | HD5870 |
|---|---|---|
| r=1 | 3.5 s (0.57 Gflop/s) | 8.1 s (0.25 Gflop/s) |
| r=2 | 1.3 s (1.5 Gflop/s) | 3.7 s (0.54 Gflop/s) |
| r=4 | 560 ms (3.6 Gflop/s) | 2.0 s (1.0 Gflop/s) |
| r=8 | 300 ms (6.7 Gflop/s) | 1.2 s (1.7 Gflop/s) |
| r=32 | 420 ms (4.8 Gflop/s) | 810 ms (2.5 Gflop/s) |
| r=128 | 685 ms (2.9 Gflop/s) | 920 ms (2.2 Gflop/s) |
This kernel is terribly slow. Interestingly, it actually illustrates almost every possible bad pattern of GPU use... Let's try to find the issues using ATI Stream Profiler. This tool integrates in Visual Studio 2008, and collects several measures from each task executed by the GPU.
Kernel profiling on the HD5870
We will profile various versions of this kernel on the HD5870 for n=224 and r=32. Each kernel will process 6 iterations, and consequently the kernel will be executed 4 times.
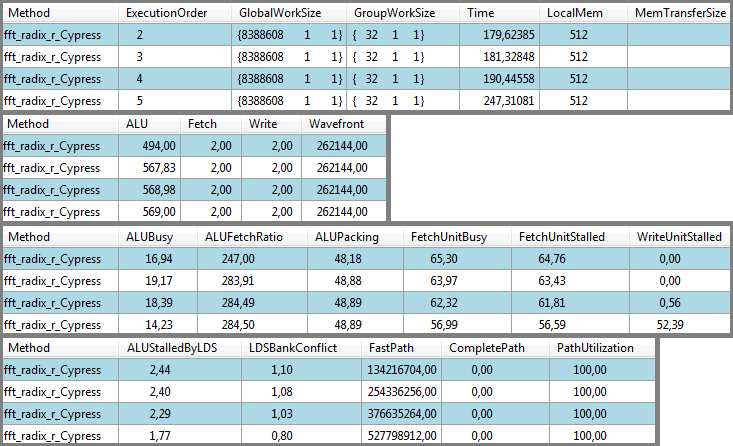
We will consider only the first kernel run (task 2). The total number of threads (GlobalWorkSize) was n/2=8388608. These threads were executed by work-groups of size 32 (GroupWorkSize), resulting in 262144 wavefronts (Wavefront).
Each wavefront (the ATI equivalent of a warp) consists in 64 threads. Here, only 32 threads of each wavefront were used. It is more efficient to have at least 64 threads in a work-group.
The total kernel execution (all threads) required 180 ms (Time). The 2 Fetch correspond to x access, and the 2 Write to y access. The value FetchUnitStalled equal to 65% of total time (117 ms) shows were the most important bottleneck is in our kernel. It means that the access pattern to array x does not allow efficient coalescent accesses. We may even be in the worst case, where all accesses are executed sequentially. Let's modify slightly the kernel (it won't compute the correct FFT anymore) to have a more regular access to x:
u[i] = mul( (float2)(cs,sn), x[get_group_id(0) + i * get_num_groups(0)] ); ... u[i+r] = mul( (float2)(cs,sn), x[get_group_id(0) + (i+r) * get_num_groups(0)] ); is replaced with: u[i] = mul( (float2)(cs,sn), x[get_global_id(0)]); ... u[i+r] = mul( (float2)(cs,sn), x[get_global_id(0)+get_global_size(0)]);

We see the huge difference: the first kernel run now takes only 34 ms. There is an equivalent problem with the write accesses to y in the last kernel run. Supposing global memory access patterns fixed, we now have a radix-64 DFT running in more or less 30 ms, which is pretty slow since it was the duration of the entire FFT in the previous page.
128 threads per work-group
We will now run kernels with r=128 threads per work-group. Each work-group now requires 2 entire wavefronts instead of one half, so we can expect better performance. By enabling/disabling various portions of the kernel code, we can measure good estimates of the time need by each step (for one run of the kernel, processing a radix-256 DFT):
- Read x to u and write u to y, coalesced global read/write: 2.6 ms.
- Read and scale (sincos+mul) x to u, and write u to y, coalesced global read/write: 3.7 ms.
- Read x to u, compute radix-2r DFT with constants (no sincos), and write u to y, coalesced global read/write: 6.5 ms.
- Read and scale (sincos+mul) x to u, compute radix-2r DFT with constants (no sincos), and write u to y, coalesced global read/write: 9.6 ms.
- Read and scale (sincos+mul) x to u, compute radix-2r DFT with sincos, and write u to y, coalesced global read/write: 22 ms.
- Read and scale (sincos+mul) x to u, compute radix-2r DFT with sincos, and write u to y, non-coalesced memory access pattern: 270 ms (this is the only one really computing the correct DFT).
In the next page, instead of storing operands in local memory, we will store them in registers, and use local memory for transferts only: One work-group per DFT (2).
| OpenCL FFT (OLD) : Radix-r kernels benchmarks | Top of Page | OpenCL FFT (OLD) : One work-group per DFT (2) |
